서론
우리가 익숙한 프로그래밍 방식은 명령형 프로그래밍일 것이다.
명령형 프로그래밍 방식은 컴퓨터에세 정해진, 명확한 지시를 하나하나 내린다는 뜻이다.
예를 들어 이 변수의 값을 10으로 바꿔줘, 이 라인을 n번 반복해줘 등이 있겠다.
처음에는 단순해 보이므로 명령형을 사용하지만 프로그램이 커질수록 복잡성이 증가한다.
유지보수하기 어려워지고, 테스트하기 어려워지고, 코드가 어떤 목적의 코드인지 추론하기 어려워진다.
함수형 프로그래밍은 명령형의 대안으로, 위에서 말한 문제들을 해결할 수 있다.
함수형 프로그래밍의 전제는 순수함수를 통해 프로그램을 구성한다는 것이다.
순수 함수란 아무런 부수 효과(Side Effect)가 없는 함수를 말한다.
결과를 반환하는 행위 이외에 다른 일을 하는 함수가 부수 효과가 있는 함수이다.
부수 효과를 일으키는 함수의 예시는 다음과 같다.
- 블록 외부 영역에 있는 변수를 변경한다.
- 데이터 구조를 In-place로 변경한다.(메모리의 내용을 직접 변경)
- 객체의 Field를 설정한다. (Setter)
- 예외를 던지거나, 예외를 발생시키며 프로그램을 중단시킨다. (Exception)
- 콘솔에 출력을 하거나 사용자 입력을 얻는다. (I/O)
- 파일을 읽거나 쓴다 (File I/O)
- 화면에 무언가를 그린다.
이런 부수효과를 일으키는 함수를 사용하지 않고 어떻게 유용한 프로그램을 작성할 수 있을까.
파일을 읽고 쓰거나, 화면에 무언가를 그리거나, 변수를 값을 변경할 수 없다는 뜻일까?
함수형 프로그래밍은 프로그램을 어떻게(How) 작성하냐에 대한 것이지, 무엇(What)을 작성하는지에 대한 것이 아니다.
순수함수를 사용해서도 위의 작업들을 할 수 있다.
함수형 패러다임을 따르면서 개발하면 더 나은 모듈성을 얻을 수 있고, 이로인해 테스트, 재사용, 병렬화, 결과 추론이 쉬워진다.
이번 장에서는 부수효과가 있는 명령형 코드들을 함수형 스타일로 리팩토링해보고, 함수형 프로그래밍의 필수 개념인 참조 투명성과 치환 모델에 대해 알아본다.
1.1 FP의 장점

카페에서 신용카드로 커피를 구매하고, 거래 비용을 처리하는 프로그램을 예시로 들겠다.
명령형 프로그램에서 부수효과를 줄인 함수형 프로그램으로 개선하는 과정을 담는다.
1.1.1 부수효과가 있는 프로그램
class Cafe {
fun buyCoffee(cc: CreditCard): Coffee {
val cup = Coffee()
cc.charge(cup.price)
return cup
}
}
class CreditCard {
fun charge(price: Int) {
TODO("신용카드사에 결제 요청")
}
}
data class Coffee(val price: Int = 4500)buyCoffee 메소드는 커피를 만들고 신용카드사에 결제를 요청하고, 커피를 반환한다.
카드를 통해 결제하면 카드사의 외부시스템으로 요청을 보내야한다. 여기서 부수효과가 발생한다.
이 코드로 테스트를 한다면 매번 실제 외부 시스템의 요청을 해야하므로, 테스트 하기가 어려워진다.
설계를 바꿔 테스트 성을 높일 수 있다.
CreditCard가 신용카드사에 접속해 비용을 청구하는 방법을 모르게 하면 된다.
class Cafe {
fun buyCoffee(cc: CreditCard, p: Payments): Coffee {
val cup = Coffee()
p.charge(cc, cup.price)
return cup
}
}
class Payments {
fun charge(creditCard: CreditCard, price: Int) {
TODO("신용카드사에 결제 요청")
}
}
data class CreditCard(val serial: String, val company: String)
data class Coffee(val price: Int = 4500)Payments라는 클래스를 새로 추가해서, 비용을 청구하는 방법은 Payments 클래스가 알고있도록 변경했다.
Payments를 인터페이스로 만들고 Mock Payments를 만들어서 테스트를 할 수 있다.
하지만 여전히 p.charge를 통해 외부 세계와 상호작용하고 있기 때문에 부수효과는 존재한다
그리고 Mock을 작성하는 것도 이상적이지는 않다. 구체화된 클래스 하나로 충분할 수도 있는데 불필요하게 인터페이스를 만들어야한다.
Mock 구현도 불편한 부분이 있다. 예를 들어 charge를 호출 한 후 이 상태가 제대로 변경되었는지를 검사해야하는 로직이 필요하기도 하고, buyCoffee를 호출하고 이를 살펴볼 수 있는 내부 상태가 필요할 수도 있다.
이런 세부 사항들을 프레임워크를 통해 처리하게 할 수 있지만 비용 청구 테스트만을 위해 프레임워크까지 사용하는 것은 오버일 수 있다.
그리고 재사용하기도 어렵다.
여러잔의 커피를 구매하면, 개수만큼 신용카드사에 요청이 발생한다.
각 요청마다 수수료가 있다면 모든 주문을 모아 한 번만 요청하는 것이 이상적이다.
1.1.2 부수효과 제거하기
- 부수효과가 있는 상황

- 부수효과가 없는 상황

buyCoffee 안에서 청구를 하는 게 아니라 청구 정보를 커피와 같이 리턴하여 청구 정보는 다른 곳에서 처리하도록 바꾼 것이다.
class Cafe {
fun buyCoffee(cc: CreditCard): Pair<Coffee, Charge> {
val cup = Coffee()
return cup to Charge(cc, cup.price)
}
}
data class Charge(val cc: CreditCard, val amount: Int) {
fun combine(other: Charge): Charge = if (cc == other.cc) Charge(
cc,
amount + other.amount
) else throw Exception("Cannot combine charges to different cards")
}
data class CreditCard(val serial: String, val company: String)
data class Coffee(val price: Int = 4500)이렇게 금액 청구를 만드는 관심사와 청구를 처리하는 관심사를 분리했다.
같은 CreditCard의 청구 정보를 하나로 만들 때 편리하게 쓸 수 있는 combine 함수도 정의하였다.
val charge1 = cafe.buyCoffee(cc)
val charge2 = cafe.buyCoffee(cc)
charge1.combine(charge2)이런식으로 사용할 수 있다.
이제 커피 n잔을 주문할 수 있는 buyCoffees를 만들어보자.
class Cafe {
fun buyCoffee(cc: CreditCard): Pair<Coffee, Charge> {
val cup = Coffee()
return cup to Charge(cc, cup.price)
}
fun buyCoffees(cc: CreditCard, n: Int): Pair<List<Coffee>, Charge> {
val purchases = List(n) { buyCoffee(cc) }
val (coffees, charges) = purchases.unzip()
return coffees to charges.reduce { c1, c2 -> c1.combine(c2) }
}
}이렇게 작성할 수 있다.
List(n) { buyCoffee(cc) }를 하면 List<Pair<Coffee, Charge>>가 만들어진다.
unzip()를 하면 Pair<List<Coffee>, List<Charge>> 가 반환된다.
그리고 구조분해를 통해 coffees => List<Coffee>, charges => List<Charge>가 각각 할당된다.
그 다음 reduce를 통해 charges의 값들을 combine한다.
이제 buyCoffees를 정의할 때 buyCoffee를 재사용할 수 있었고, 관심사를 분리하였기 때문에 굳이 Payments 인터페이스와 mock 을 정의하지 않아도 쉽게 테스트할 수 있다.
실제 금액 청구는 Payments 같은 클래스가 필요하겠지만 Cafe 클래스는 Payments를 몰라도 된다.
우리는 Charge를 일급 객체(First-class value)로 만들었다. 일급 객체로 만들면 청구 금액을 처리하는 비지니스 로직을 더 쉽게 조립할 수 있다는 장점이 생긴다.
➤ 일급 객체란 다음 3가지 조건을 만족하는 객체이다.
- 다른 변수나 데이터에 담을 수 있어야한다.
- 함수의 파라미터로 전달될 수 있어야한다.
- 함수의 반환값으로 사용될 수 있어야한다.
일급 객체이기 때문에 일련의 Charge List가 있을 때 같은 카드에 청구하는 금액을 모두 합치는 로직을 쉽게 작성할 수 있다.
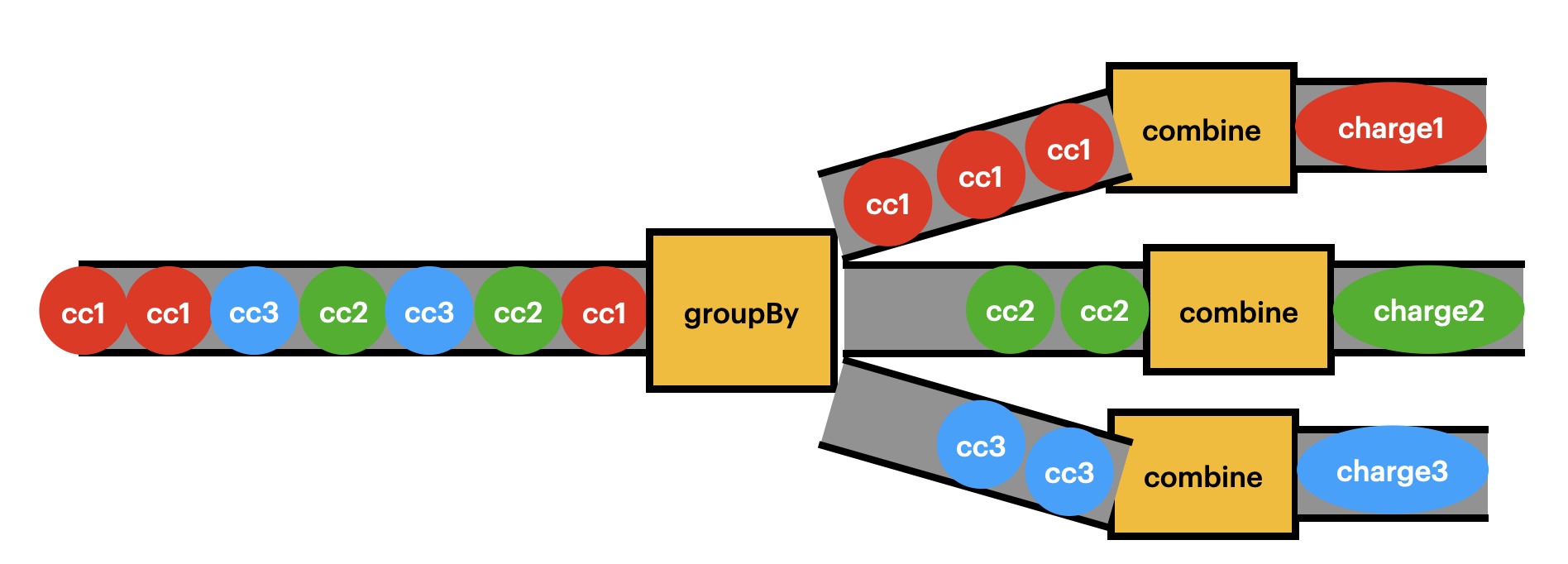
fun List<Charge>.coalesce() =
this.groupBy { it.cc }.values
.map { it.reduce {c1, c2 -> c1.combine(c2)} }이렇게 하여 사용한 신용카드에 따라 그룹으로 나누고 각 그룹의 청구금액을 하나로 합친 Charge List를 만들어낸다.
fun main() {
val cc1 = CreditCard("1234", "K")
val cc2 = CreditCard("2345", "H")
val cc3 = CreditCard("3456", "W")
val chargeList = listOf(
Charge(cc1, 3000),
Charge(cc2, 4000),
Charge(cc3, 5000),
Charge(cc2, 3800),
Charge(cc2, 4500),
Charge(cc1, 4000),
Charge(cc1, 5500)
)
val result: List<Charge> = chargeList.coalesce()
}이런식으로 사용할 수 있고 그림으로 보면 다음과 같다.
1.2 순수 함수란?
정확하게 순수함수를 정의해보자. 형식적(제한된 단어를 사용해서 엄격하고 정확하게 기술)인 정의이다.
앞에서 함수형 프로그래밍은 순수함수를 이용해 프로그래밍 하는 것이라 했다. 그리고 순수함수란 부수효과가 없는 함수라고도 했다.
입력이 A이고 출력이 B인 함수 f가 있다고 하자. 코틀린에서는 (A) -> B 이렇게 쓴다.
A 타입이 될 수 있는 모든 값 a 를 B 타입이 될 수 있는 모든 값 b에 매핑해주는 계산이다. b값은 a값에 의해서만 결정이된다.
f(a) = b의 식에서 내부, 외부의 상태 변경은 결과에 영향을 끼치지 못한다.
*의문점
내부의 상태 변경은 영향을 끼칠 수 있는 것 아닌가? a값과 연관이 없는 내부의 상태변화를 이야기 하는 것인가?
이러한 정의에 따른 순수함수의 예시는 +(plus)연산과 String.length() 연산이 있다.
plus의 경우 두 정수가 주어지면 항상 같은 결과값을 반환한다.
Java, Kotlin의 String은 불변 객체이기 때문에 주어진 문자열에 대해 "string".length()를 호출하면 항상 같은 결과가 반환된다.
"string"라는 리터럴은 변할 수 없기 때문이다.
불변 객체란? 객체의 내부 프로퍼티를 변경할 수 없는 객체이다.
예를 들어
var str = "Hello"
str = "World"이렇게 변수를 변경한다고 해도, Hello라는 String 인스턴스의 값이 World로 변경된 것이 아니라.
Hello라는 인스턴스는 그대로 있는 상태에서 World라는 인스턴스가 새로 생성되고, str의 참조값이 바뀌는 것이다.
순수함수의 개념을 참조 투명성(RT; Referential Transparency)의 개념을 이용해 형식화 할 수 있다.
참조 투명성이란?
예를 들어 2+3 이라는 식이 있을 때, 프로그램 안에서 2+3이라는 식을 모두 5로 치환할 수 있고, 그렇게 해도 프로그램의 의미가 전혀 변하지 않는다.
어떤 식이 "참조 투명하다"라고 말하는 것은 프로그램의 의미를 변경하지 않으면서 식을 그 결과값으로 치환할 수 있다는 것이다.
참조 투명한 인자를 사용해 호출한 함수의 결과가 참조 투명하다면 이 함수도 참조 투명하다.
형식화된 정의
어떤 식 e에 대해, 모든 프로그램 p에서 e를 e의 결과값으로 치환해도 p의 의미에 변화가 없다면 e는 참조 투명하다.
어떤 함수 f가 있을 때, 참조 투명한 x에 대해 f(x)가 참조 투명하다면 함수 f도 참조 투명하다.
∴ 참조 투명한 함수를 순수함수라고 한다.
1.3 참조 투명성, 순수성, 치환 모델
어떤 함수가 참조 투명하다면, 함수를 함수의 결과값(반환값)과 치환할 수 있다고 했다.
우리가 가장 처음에 봤던 부수효과가 있는 buyCoffee 함수를보자.
fun buyCoffee(cc: CreditCard): Coffee {
val cup = Coffee()
c.charge(cup.price)
return cup
}이 함수는 cc.charge()의 결과와는 상관없이 cup을 반환한다.
참조 투명성에 정의에 의해 buyCoffee가 순수함수가 되려면 모든 프로그램 p에 대해서 buyCoffee를 Coffee()로 치환할 수 있어야한다.
하지만 p(buyCoffee())는 p(Coffee())와 같지 않다. charge를 하지 않기 때문이다.
이렇게 단순히 치환된다고 참조 투명성이 있는 것이 아니다.
함수가 수행하는 모든 일이 함수의 반환 값에 의해 표현되어야 한다.
이런 제약이 있을 때 참조 투명성이 있다고 할 수 있고, 치환 모델을 통해 프로그램 추론이 쉬워진다.
* 치환 모델을 사용한다는 건 함수를 함수의 결과값으로 치환해서 계산한다는 것이다.
참조 투명성이 확보되면 우리가 대수 방정식을 푸는 것처럼 코드를 읽을 수 있다.
* 대수방정식은 미지수(x, y..)가 포함된 식을 말한다.
4x - 6 = 10 ⇢ ⓵
2y + 3x = 16 ⇢ ⓶
1번 식을 통해 x=4라는 답이 나왔다. 그럼 2번 계산에서 x를 4로 치환해서 계산해도 전혀 문제가 없다.
코드를 통해 치환 모델의 예시를 살펴보자.
1. 참조 투명한 식에 치환 모델 적용
위에서 말한대로 코틀린의 String은 불변객체이다. 문자열에 +를 하거나, reversed()를 하거나 문자열은 변경되지 않는다. 새로운 문자열 인스턴스가 할당될 뿐.
val x = "Hello, World"
val r1 = x.reversed() // dlroW ,olleH
val r2 = x.reversed() // dlroW ,olleH치환 모델을 사용해보자. 즉, x를 "Hello, World"로 치환해보자는 뜻이다.
val r1 = "Hello, World".reversed() // dlroW ,olleH
val r2 = "Hello, World".reversed() // dlroW ,olleH프로그램에 아무 영향이 없다. x가 참조 투명하기 때문이다.
그리고 x가 참조 투명하기 때문에 r1, r2 도 참조 투명하다.
2. 참조 투명하지 않은 시에 치환 모델 적용
val x = StringBuilder("Hello")
val y = x.append(", World")
val r1 = y.toString() // Hello, World
val r2 = y.toString() // Hello, WorldStringBuilder는 String과 달리 객체 내부의 상태를 변경한다.
현재 코드에서는 r1, r2가 같다 하지만, y를 치환한다면 어떻게 될까?
val x = StringBuilder("Hello")
val r1 = x.append(", World").toString() // Hello, World
val r2 = x.append(", World").toString() // Hello, World, Worldr2의 값이 할당되는 시점에 x의 값이 변경되었기 때문에 다른 결과가 나왔다.
따라서 append는 순수함수가 아니라고 할 수 있다. 그리고 이런 코드는 추론하기가 힘들다.
치환 모델을 사용하면 식이나 코드를 추론하기 더 쉬워진다. "x가 여기선 어떻게 변경되고 다음 상태에선 어떻게 되겠지" 이런 시뮬레이션을 안해도 된다.
'Programming > 코틀린 함수형 프로그래밍' 카테고리의 다른 글
| 5. 엄격성과 지연성 (0) | 2023.10.15 |
|---|---|
| 함수형 프로그래밍의 Fold(FoldLeft, FoldRight의 차이점) (1) | 2023.09.18 |
| 4. 예외를 사용하지 않고 오류 다루기 - Functional Programming in Kotlin (0) | 2023.09.10 |
| 3. 함수형 데이터 구조 - Functional Programming in Kotlin (0) | 2023.09.10 |
| 2. 코틀린으로 함수형 프로그래밍 시작하기 - Functional Programming in Kotlin (0) | 2023.09.06 |